Three Questions Before You Build Your Own AI Platform
Data residency, model sizing, and API surface — answered before the first GPU ships
Marcelo Katogui
April 23, 2026
1. The Wrong Starting Point
Building AI infrastructure does not start with picking a model. Most teams begin there — evaluating benchmarks, negotiating API contracts, provisioning GPUs — and most teams regret it. The hardware and software decisions that define a platform are downstream of three questions about where work runs, what data crosses boundaries, and what shape consumers expect. Answer those and the architecture falls out on its own.
A workstation-scale AI platform — chat, vision, transcription, PDF extraction, semantic search, document QA, multi-step reasoning, all behind a single OpenAI-compatible API — is not built by selecting a model. It is built by answering these three.
The Platform Triage. Every AI infrastructure decision reduces to three prior questions: (1) what data cannot leave the building, (2) what workloads do not require a frontier model, and (3) what interface surface do consumers expect. Hardware choices follow from these answers. They do not precede them.
2. What Cannot Leave the Building?
Start here. This question eliminates most of the decision tree.
Documents under NDA, customer data carrying GDPR obligations, intellectual property that constitutes competitive moat — if any of these categories exist, inference must run on controlled infrastructure. The alternative is not a policy decision. It is a liability.
Most teams arrive at this answer by pain, not by planning. They ship on a cloud API, discover a year later that privileged data has been flowing to a third party, and attempt to bolt on controls after the fact. The retrofit is always more expensive than the upfront decision.
The Tokenization Trap. A middle tier exists: tokenize sensitive fields at the boundary, send only scrubbed payloads to external endpoints. This pattern is valid — and incomplete. It solves one class of leakage. It does not address training loops, prompt-injection exfiltration, or the fact that query patterns in someone else’s logs constitute a signal about organizational intent. Scrubbing the payload is not the same as controlling the channel.
The decision rule is binary. If nothing sensitive touches the system, use a cloud provider and avoid the operational overhead. If significant categories of data must remain internal, build on controlled hardware and accept the tradeoff. The middle ground exists, but it is narrower than it appears.
3. What Does Not Need a Frontier Model?
This is where most over-engineering happens.
A growing category of work — classification, entity extraction, structured output, retrieval, embedding, routing — runs well on small specialized models or non-neural heuristics. The failure mode is not underspending. It is paying per-token for a 70-billion-parameter model to decide whether an inbound email is a lead.

Most AI workloads cluster in the fast-and-small quadrant. The expensive frontier tier handles a minority of total request volume.
The correct mapping is workloads by capability required, not capability available. Greetings, intent classification, routing decisions, embedding generation — milliseconds on a local model. The expensive tier is reserved for genuinely hard reasoning.
This is not primarily a cost argument. It is a latency argument. Small fast models feel responsive; large slow models feel sluggish. User experience compounds over every interaction. A system that routes 80% of requests to a sub-100ms model and reserves the large accelerator for the remaining 20% will outperform — in perceived quality — a system that sends everything to the biggest model available.
The expected latency for a routed request can be expressed as a weighted sum:
\[\bar{L} = \sum_{k=1}^{K} \pi_k \cdot \ell_k\]
where \(\pi_k\) is the fraction of traffic routed to tier \(k\) and \(\ell_k\) is the mean latency of that tier. When \(\pi_1\) (the small-model share) is large and \(\ell_1\) is small, the system-wide average drops dramatically — even if the frontier tier is slow.
4. What Surface Do Consumers Expect?
Building for internal tooling? Invent whatever interface is most natural.
Building for external integrations, customers, partners, or any
workflow platform? Conform to the OpenAI API shape. Every SDK, every
orchestration framework, every developer with a curl
command already speaks it. Adopting this interface saves months of
integration work that would otherwise be spent on custom client
libraries and documentation that no one reads.
Interface Principle
The OpenAI-compatible API surface is not a technical standard. It is an ecosystem standard. Adopting it is not about endorsing a vendor — it is about inheriting the integration work of every tool that already implements the interface. The cost of inventing a new surface is not the initial build. It is the perpetual maintenance of something no one else supports.
This is not a technical preference. It is a network-effects calculation. The interface that the ecosystem already speaks is the one that costs the least to maintain and the most to deviate from.
5. Match Compute to the Shape of the Work
Once the three questions are answered, hardware architecture follows directly. A workstation-class platform holds four distinct compute resources, each matched to a class of work:
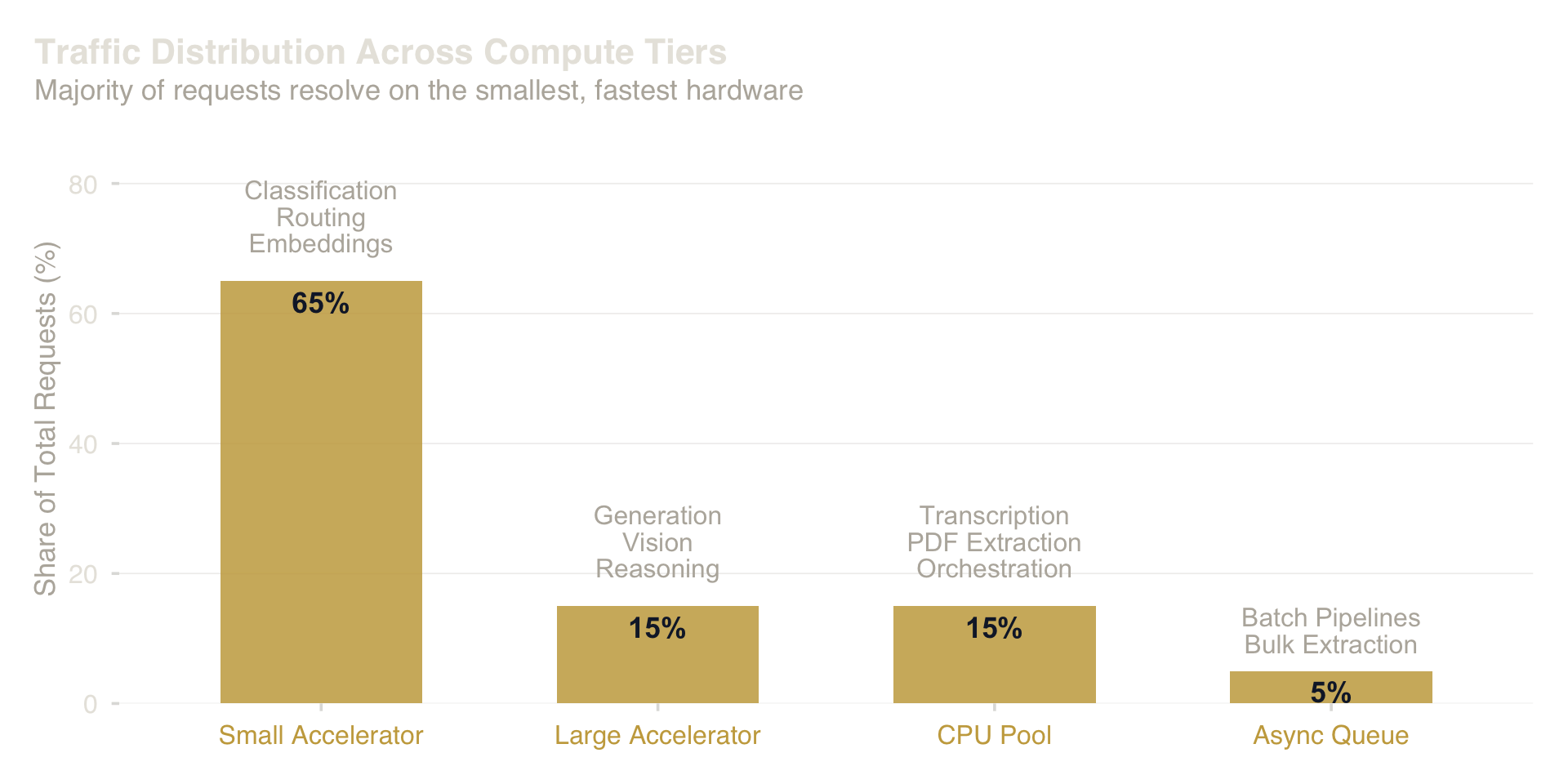
Four compute tiers mapped to workload characteristics. The router is the most valuable component — it makes the hardware feel unified.
- Small always-on accelerator — classification, routing, embeddings. Millisecond latency. Handles the high-frequency work that constitutes the majority of traffic.
- Large parallel accelerator — generation, vision, attention-heavy reasoning. Second-scale latency. Handles the genuinely hard problems.
- CPU pool — transcription, PDF extraction, database queries, orchestration. Everything that is not a neural forward pass.
- Async queue — anything longer than about a minute. Overnight pipelines, bulk extraction across thousands of files.
The router in front of these tiers is the most valuable piece of the system. It classifies each request in milliseconds and dispatches to the correct resource. A good router makes the hardware feel unified. A bad router sends everything to the large accelerator and wonders why the system is perpetually saturated.
6. The Breadth That Follows
This is the part that organizations underestimate. The platform is not built for one use case. Once the compute shape is right, the same infrastructure serves every modality:
- Conversational — chat, multi-turn Q&A, streaming replies
- Vision — image understanding, receipts, invoices, screenshots
- Audio — transcription, dictation, interviews, multi-language speech
- Documents — PDF extraction, table parsing, OCR-plus-understand
- Knowledge — RAG retrieval, semantic search over private corpora, citation-grounded answers
- Structured extraction — papers, contracts, emails into JSON
- Classification — intent routing, spam detection, sentiment
- Generation — emails, proposals, summaries, reports
- Batch / async — overnight pipelines, bulk extraction at scale
- Web — search-and-summarize, scrape-and-extract
- Orchestration — multi-step chains, tool use, task decomposition
One box. One router. One interface.
Distinct capability categories served by a single routed platform
The honest limit: genuinely novel frontier reasoning. If the workload requires the most capable model on earth at the moment of inference, reach for the cloud. Most workloads do not.
7. When This Is the Wrong Answer
Not every organization should build this. Three conditions make it the wrong choice:
The Ops Reality. A dozen services behind a router is real operational work. If no one is accountable for keeping the platform running — monitoring, patching, model updates, disk failures — the system degrades silently. An unmaintained platform is worse than no platform, because it creates false confidence in capabilities that have quietly stopped working.
Low and sporadic volume. Pay-per-token vendors amortize infrastructure costs across millions of users. An idle workstation is opportunity cost — capital deployed for capacity that sits unused. If the organization’s AI workload is measured in hundreds of requests per day rather than thousands per hour, the economics favor cloud APIs.
Genuine frontier dependence. For leading-edge research, user-facing creative generation at the highest quality tier, or domains where model capability is the binding constraint rather than latency or data residency — the right answer is to buy the best available model from the provider who updates it fastest.
8. Where to Start
Do not start by picking a model. List the workloads the organization needs to serve and for each one answer:
- Can this data leave the building?
- What is the smallest model that satisfies the quality requirement?
- What interface do consumers expect?
Write the answers down. Once they are on paper, the hardware and software choices fall out on their own. The expensive components are smaller and fewer than vendor marketing would suggest. The interface is already decided. And the platform — the actual platform — is not a model.
It is the shape of the answer to those three questions.
References
- Bommasani, R., Hudson, D. A., Adeli, E., et al. (2021). On the Opportunities and Risks of Foundation Models. arXiv:2108.07258.
- Paleyes, A., Urma, R.-G., & Lawrence, N. D. (2022). Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Computing Surveys, 55(6), 1–29.
- Sculley, D., Holt, G., Golovin, D., et al. (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems, 28.
- Liang, P., Bommasani, R., Lee, T., et al. (2023). Holistic Evaluation of Language Models. Transactions on Machine Learning Research.
- Vaidhyanathan, S. (2018). Antisocial Media: How Facebook Disconnects Us and Undermines Democracy. Oxford University Press.