Engineering a Production-Grade Shiny Infrastructure
From Proof of Concept to a Reproducible, Observable, and Validated Data Product
Marcelo Katogui
February 25, 2026
How we transformed a “Proof of Concept” (GitHub | Live App) into a technical template for reproducible, observable, and validated data products.
Executive Summary
This document presents the engineering decisions behind the PoC Cascade Filtering project — a Shiny web application that was deliberately over-engineered as a blueprint for production-grade data products. You can interact with the live application here.
The Problem
Most Shiny applications start as quick prototypes. They work on the developer’s machine, get demonstrated to stakeholders, and are declared “done.” But when these apps need to scale — when a second developer joins, the server moves to a container, or the business relies on the output for decisions — they fail in unpredictable ways. The root cause is always the same: the prototype was never designed for the environment it ended up in.
What We Built
We identified five independent failure modes that cause prototypes to break in production, and engineered a specific solution for each:
| Risk | What goes wrong | Our solution |
|---|---|---|
| Scattered rules | Business logic is copy-pasted across files; rules change in one place but not another | A single validation engine where every rule is defined once and tested automatically |
| Empty screens on load | Users briefly see blank dropdowns before the server catches up | UI elements arrive pre-populated — no waiting, no flicker |
| “Works on my machine” | The app runs locally but crashes in the cloud due to invisible software differences | A triple-lock container strategy that freezes every dependency |
| Invisible failures | When something goes wrong in production, nobody knows until a user complains | Structured machine-readable logs that can feed into any monitoring dashboard |
| Broken code reaching users | A developer pushes a bug, and it goes live before anyone catches it | A four-stage quality gate where a single failure blocks deployment |
The Infrastructure Mapping table (§1) maps each of these risks to its detailed engineering pattern and failure mode.
The Evidence
- Build time dropped 90% by using pre-compiled packages matched to the container’s operating system.
- Zero broken containers have been shipped since adopting the triple-lock strategy.
- 100% of tests must pass before any code can reach production — there are no manual overrides.
- Every deployment is automatically versioned with a semantic release tag, creating a full audit trail.
How to Read This Document
- If you are a project manager or stakeholder: This summary and the Key Takeaways (§9) give you the business picture. The Infrastructure Mapping table (§1) maps each risk to its solution. The Limitations (§10) tell you what this blueprint does not cover.
- If you are an engineer or tech lead: The full document provides the technical detail — code samples, diagrams, formal invariants, and the reasoning behind each design choice.
- If you want to try it yourself: The GitHub repository contains the complete source code, Dockerfile, CI/CD pipeline, and test suite.
Business Impact
Every engineering decision in this document maps to a business outcome:
| Engineering Decision | Business Outcome |
|---|---|
| Single validation engine (§2) | Reduced rework. When a business rule changes, it is updated in one file and automatically enforced everywhere. No developer time is spent hunting for scattered copies of the old rule. |
| Pre-populated UI elements (§3) | Better user experience. Users never see empty screens or broken dropdowns. First impressions of the tool are consistently professional. |
| Triple-lock containers (§4) | Reliable deployments. Releases that used to take 15 minutes now take under 2. The “it worked yesterday but not today” class of failure has been eliminated entirely. |
| Structured logging (§5) | Proactive issue detection. Problems surface in monitoring dashboards before users report them. Support tickets decrease because failures are caught and diagnosed automatically. |
| Four-stage quality gate (§6) | Lower risk per release. Every change is verified by four automated checks before it reaches users. No human can accidentally skip a step or override a failing test. |
| Automatic semantic versioning | Full audit trail. Every production release is tagged, traceable, and reversible. Compliance and governance requirements are satisfied by default. |
The cost of not doing this is invisible — until it isn’t. A prototype that “works” costs nothing extra today. But the first production outage — the missed demo, the corrupted report, the compliance audit that asks “which version was running on March 3rd?” — costs far more than the infrastructure that would have prevented it.
Regulatory Readiness
For organizations in regulated industries (pharma, finance, clinical research), the engineering patterns already map to established compliance frameworks:
| Area | What This Document Demonstrates | Framework |
|---|---|---|
| Audit trail | Structured JSON logs with session tokens and ISO-8601 timestamps | ALCOA+ / 21 CFR Part 11 — see §5 for full mapping |
| Reproducibility | Pinned packages + pinned OS image = identical builds years apart | GxP / GAMP 5 |
| System qualification | Unit tests (IQ), E2E tests (OQ), deployment guard (PQ) | IQ/OQ/PQ — see §6 for full mapping |
| Change control | Semantic versioning + release tags on every merge | GxP / ICH Q10 |
| Single Source of Truth | All business rules and constants defined once in
R/constants.R
|
GAMP 5 Category 5 |
A Note on Scope
These patterns provide the engineering foundation on which a formal validation protocol (IQ/OQ/PQ) can be built. They do not constitute a validation master plan or risk assessment matrix — but they eliminate the most common reason validation efforts fail: the underlying code was never engineered to be validatable in the first place.
1. The Engineering Challenge: “The PoC Trap”
The Executive Summary names the problem in business terms: prototypes that “work” fail in production. This section explains why — the specific structural failures that cause the collapse.
We call it the PoC Trap: the false confidence that a working prototype implies a production-ready system. The same discipline we apply to statistical validation — ensuring that your evaluation mechanism matches your deployment reality — applies equally to software infrastructure. A model that overfits to its training data is no different from a Shiny app that “works on my machine.”
Validation logic becomes scattered across UI tags and server observers.
if/else blocks are duplicated across modules. When a
business rule changes, some instances are updated and others are not.
The validation cannot be audited or tested in isolation — and the
divergence is invisible until a user triggers a code path that still
enforces the old rule.
Dependency conflicts lead to brittle deployments that fail silently in
production. A package that compiled against one C++ standard library
crashes when the container ships a different ABI. The error message —
undefined symbol — is indistinguishable from an application
bug. The developer who can reproduce it differs from the one who cannot,
and the root cause is not in any .R file.
Named for its opacity: you cannot see through the reactive graph. Race conditions in modules cause intermittent UI failures that are nearly impossible to debug without structured logs. A modal dialog opens before the server has finished populating its dropdowns. The user sees an empty list, selects nothing, and submits an invalid state. In manual testing this happens “sometimes.” In automated testing it fails consistently — but only if the test framework is fast enough to catch the window.
In this project, we set out to build a Blueprint for Production-Grade Shiny, using the PoC_Cascade_Filtering system (available as a live application) as our case study. The project requirements were deceptively simple: a category → subcategory → product cascade with modal editing. The engineering requirements were not.
Infrastructure Mapping
Before choosing an infrastructure pattern, define the deployment scenario precisely. The table below maps common production requirements to the engineering patterns developed in this case study:
| Production Requirement | Failure Mode Without It | Engineering Pattern |
|---|---|---|
| Reproducible across machines | “Works on my machine” syndrome | Triple-Lock containers (§4) |
| Testable without a browser | Validation logic buried in UI | Unified Validation Engine (§2) |
| No flash-of-empty-content on load | Modal race conditions | UI-populated choices (§3) |
| Debuggable in production | Silent failures, no audit trail | Structured JSON logging (§5) |
| Automated quality gate before deploy | Broken code reaches users | Green Light pipeline (§6) |
The correct engineering pattern follows directly from the deployment scenario — just as the correct CV split follows from the deployment target. Mismatching the two is the root cause of production failures.
Core Principle
Production-Grade Shiny isn’t about the complexity of the UI. It’s about the integrity of the infrastructure — treating R code with the same discipline as a backend API. The PoC Trap is a form of overfitting: the prototype “generalizes” perfectly to the developer’s machine, but fails on every other environment it encounters.
2. Architecture: The Unified Validation Engine
The core of the application is a Unified Validation
Layer (R/validation.R). Unlike traditional Shiny
apps that perform ad-hoc checks in scattered if/else
blocks, we implemented a centralized engine driven by discrete, testable
invariants.
The motivation is structural. In a typical Shiny application,
validation logic is embedded directly in observeEvent()
handlers — interleaved with UI updates, database calls, and reactive
side effects. This makes the validation impossible to test without
launching a full Shiny session. Worse, when two modules enforce the same
business rule, they inevitably diverge over time: one gets updated, the
other does not, and the app enters an inconsistent state where the same
input is valid in one context and invalid in another.
The Unified Validation Engine eliminates this class of failure by extracting every business rule into a pure function — one that takes data in and returns a boolean, with no side effects, no reactive dependencies, and no UI coupling.
The “Parental Constraint” Pattern
We encoded business logic directly into validation functions using a hierarchical dependency chain. A Product is not just “present” — it is only valid if it belongs to a valid Subcategory, which in turn must belong to a valid Category:
Figure 1. Parental Constraint Hierarchy. Each level can only be valid if its parent is valid. This prevents any validation from being circumvented — a product cannot exist without a valid subcategory, and a subcategory cannot exist without a valid category.
The hierarchy is not cosmetic — it enforces a strict ordering.
is_valid_product() cannot return TRUE unless
is_valid_subcategory() also returns TRUE for
the same path. This makes the validation composable: each function
delegates upward, and the call chain is fully deterministic. There is no
global state, no session object, and no reactive context. A unit test
can exercise every validation path in milliseconds.
The function design makes dependencies explicit and composable:
is_valid_subcategory <- function(subcategory, category) {
category %in% VALID_CATEGORIES &&
subcategory %in% SUBCATEGORIES[[category]]
}
is_valid_product <- function(product, subcategory, category) {
# Structural invariant: path must be valid first
if (!is_valid_subcategory(subcategory, category)) return(FALSE)
# Business invariant: product must exist in sample data
product %in% (sample_data %>%
filter(Subcategory == subcategory) %>%
pull(Product))
}The Composability Invariant. If a validation function \(V_k\) depends on a parent validation \(V_{k-1}\), then \(V_k\) must call \(V_{k-1}\) internally. No validation may assume its parent has already been checked externally. This ensures that every validation is self-contained — it can be called from any context (UI observer, unit test, API endpoint) and produce the correct result.
Beyond the Cascade: Scalar Business Rules
The Unified Validation Engine validates more than hierarchical position. It also enforces three scalar business rules that accompany every filter submission:
| Field | Rule | Constant |
|---|---|---|
| Quantity | Positive integer (scalar only) | MIN_QUANTITY = 1L |
| Comment | Between 10 and 20 characters | MIN_COMMENT_LEN,
MAX_COMMENT_LEN
|
| Order Date | Between 2023-01-01 and
2026-12-31
|
MIN_DATE, MAX_DATE |
Each rule is a pure function in R/validation.R, driven
entirely by constants from R/constants.R. The UI surfaces
invalid states in real time using shinyFeedback’s
field-level inline messages — the Apply Filter button
remains disabled until all six fields (Category, Subcategory, Product,
Quantity, Comment, Order Date) are simultaneously valid. This
“all-or-nothing” gate prevents any partial submission from reaching the
server.
Disabling the Apply button is not a UX affordance — it is a correctness invariant. A partially valid submission that reaches the server can produce a valid-looking result from an invalid state. By enforcing the gate at the UI level (disabled button) and re-validating at the server level, the engine achieves defense-in-depth: the invalid state cannot be submitted, and even if it could, the server would reject it.
Zero Drift: The Constants Principle
By concentrating all boundary parameters in
R/constants.R, we achieve Zero Drift — the
same values that define dateInput minimum/maximum
boundaries also power the testthat assertions. There is a
single source of truth and it cannot diverge.
This principle addresses one of the most subtle failure modes in
application development: the copy-paste constant. A developer defines
MIN_DATE <- as.Date("2020-01-01") in the UI module, then
writes a test that checks
expect_true(result >= as.Date("2020-01-01")). The two
dates happen to match today — but when the business requirement changes,
the developer updates the UI and forgets the test. The test still passes
(it checks the old boundary), but the assertion no longer validates the
live behavior.
Invariant. If a constant is used to constrain UI behavior, the same constant must be used in the corresponding unit test. Any copy-pasted or hardcoded test boundary is a Zero-Drift violation.
Engineering Insight
The Unified Validation Engine applies the same principle as grouped CV: separate the thing being tested from the mechanism that tests it. Just as grouped CV prevents the model from borrowing signal that won’t exist at deployment, the validation engine prevents the UI from embedding logic that won’t be tested at CI time.
3. Solving the “Modal Race Condition”
One of the most persistent bugs in modular Shiny apps is the initialization race condition. When a user opens a modal dialog, the server often lags behind the UI rendering, resulting in empty dropdowns — a “flash-of-empty-content” that breaks both user experience and automated testing.
The race condition is not a timing bug in the usual sense — it is a
structural flaw in the reactive dependency graph.
Shiny’s render cycle is asynchronous: the UI definition is sent to the
browser immediately, but updateSelectInput() calls execute
in a later reactive flush. The gap between “modal visible” and “choices
populated” can be as short as 50ms on a developer’s machine and as long
as 500ms on a loaded server. The user sees the empty state for a
fraction of a second — long enough to select “nothing” and trigger a
downstream validation failure.
Anatomy of the Race
Figure 2. The Race Condition vs. The Fix. The legacy
pattern (left) creates a window where the UI is visible but dropdowns
are empty. The production blueprint (right) eliminates this window
entirely by embedding choices in the UI definition. The difference is
structural, not temporal — no amount of Sys.sleep() or
invalidateLater() can reliably close the race window.
The Fix
The solution is to move the static root of the cascade from the
server module into the UI definition
(R/filter_module_ui.R). Since VALID_CATEGORIES
is a constant (defined once in R/constants.R), it is
available at render time without waiting for a reactive cycle:
# filter_module_ui.R — choices are defined in the UI, not the server
filterModuleUI <- function(id) {
ns <- NS(id)
selectInput(
inputId = ns("category"),
label = "Category",
choices = VALID_CATEGORIES, # <-- pre-loaded from constants
selected = VALID_CATEGORIES[1]
)
}The race window is not a performance problem — it is a
correctness problem. When shinytest2 opens the
modal, it immediately queries the DOM for dropdown choices. If the
choices arrive in a later reactive flush, the test sees an empty
<select> and either fails outright or selects a null
value that cascades into downstream assertions. Pre-populating the UI
eliminates this entire class of test flakiness.
The fix has a secondary benefit: it makes the application instantly usable. There is no spinner, no loading state, and no progressive disclosure for the root level of the cascade. The user sees valid choices at the same instant the modal appears. Downstream levels (subcategory, product) are still populated reactively — but they depend on the user’s selection, so the server response latency is expected and invisible.
Engineering Insight
Any Shiny UI element whose initial value is static (does not depend
on user input or database state) should be populated in the UI
definition, not reactively on the server. This eliminates the race
window and makes the app instantly usable — including by
shinytest2 automated tests. The principle generalizes:
if the data is known at build time, embed it at build
time.
4. Deterministic Reliability: ABI-Aligned Containers
For production deployments, “Zero Internet” builds are a requirement. We achieved 100% reproducibility using a “Triple-Lock” strategy that eliminates three independent sources of build non-determinism:
Every package version is pinned at the commit level via
renv.lock. The lockfile records not just the package name
and version, but the exact repository URL and hash. A build run today
and a build run six months from now will install identical binaries.
Standardized on a Rocker base image (Ubuntu Noble) —
the exact ABI used by Posit Package Manager (PPM). The base image is
pinned by digest, not by tag, so even rocker/r-ver:latest
drift cannot affect the build.
Pre-compiled binaries from PPM eliminate C++ compilation, reducing build time by 90%. Because the binaries are compiled on the same OS as the container, the resulting shared objects are ABI-compatible by construction.
Why ABI Alignment Matters
The most subtle failure mode in R container deployments is an
ABI mismatch: the base OS ships a C++ standard library
that is newer (or older) than the one used to compile the binary
packages on the mirror. This produces cryptic
undefined symbol runtime errors that are indistinguishable
from application bugs.
The mechanism is straightforward: R packages that include compiled C
or C++ code (via Rcpp, data.table, or
system-level dependencies) link against the C++ standard library at
compile time. The resulting .so file expects specific
symbols to be present in the runtime’s libstdc++. If the
container’s libstdc++ was compiled with a different GCC
major version than the one on PPM’s build farm, the symbol table does
not match, and the package loads but crashes at the first function
call.
Figure 3. ABI Alignment. Mismatched OS and mirror ABIs
cause runtime symbol errors that surface only when a compiled package is
loaded. Selecting a Rocker image that matches the PPM build environment
eliminates this class of failure entirely — the .so files
are compiled against the same libstdc++ they will link to
at runtime.
ABI mismatches are silent until they are
catastrophic. The container builds successfully. The
renv::restore() completes without error. The application
starts. But the first time a user triggers a code path that calls into a
compiled package — data.table::fread(),
jsonlite::toJSON(), Rcpp-backed validation —
the process crashes with a symbol error that no amount of R-level
debugging can resolve. The fix is not in the code. The fix is in the
Dockerfile’s FROM line.
The Dockerfile as Verification Engine
The Dockerfile is not just a runner — it is a
verification engine. Google Chrome is installed during
the build phase to run shinytest2 headless E2E tests
before the image is tagged.
# Dockerfile — verification pipeline embedded in build
RUN apt-get install -y google-chrome-stable
# Run E2E tests DURING build — fail fast before registry push
RUN Rscript -e "shinytest2::test_app('.')"This design means that a broken container never reaches the registry. If the headless E2E tests fail — whether due to an ABI mismatch, a missing system dependency, or a genuine application bug — the Docker build fails. The production environment is never updated with a known-broken image.
The Build-Time Verification Invariant. If a test can be run without user interaction and without external network access, it must be run during the container build phase. Any test deferred to runtime is a test that can be skipped by accident — and a test that is skipped is a test that does not exist.
Infrastructure Insight
The Triple-Lock strategy mirrors the variance decomposition from
statistical validation: each lock eliminates an independent source of
variability. renv pins the package dimension, the Rocker
image pins the OS dimension, and binary mirrors pin the compilation
dimension. Together they produce a build that is deterministic across
time, machines, and developers — the infrastructure equivalent of an
exchangeability guarantee.
5. Observability: Structured JSON Auditing
Logging is almost universally an afterthought in Shiny applications.
The default behavior — cat() to the console, or
message() to stderr — produces unstructured, human-readable
text that is impossible to parse programmatically. When the app runs on
a single developer’s laptop, this is tolerable. When it runs in a
container behind a load balancer, it is useless.
We implemented a Structured Logging Layer
(R/logger.R) that emits JSON-line logs to
stderr — directly ingestible by CloudWatch, Datadog, or any
log aggregation pipeline that supports JSON-lines format.
Event Schema
| Event | Metadata | Purpose |
|---|---|---|
APP_START |
Session ID, Timestamp | Audit trail anchor |
VALIDATION_CHANGE |
IsValid, Category, Subcategory, Product | Monitor user behavior and errors in real time |
FILTER_SUCCESS |
Full selection vector, Session ID | Trace business outcomes |
The event schema covers the full session lifecycle.
APP_START creates a unique session token that correlates
all subsequent events. VALIDATION_CHANGE fires on every
state change — including invalid intermediate states — making it
possible to query exactly how many keystrokes a user takes before
reaching a valid selection. FILTER_SUCCESS records the
final business outcome: the complete selection vector (Category,
Subcategory, Product, Quantity, Comment, Order Date) that was
applied.
This structure transforms debugging from guesswork into a query.
Questions like “What fraction of sessions encounter a validation
error in the first 30 seconds?” or “Which product category has
the highest drop-off rate?” become instantly answerable with a
single jq pipeline or CloudWatch Insights query.
The Logger Implementation
# R/logger.R
log_event <- function(event, session, ...) {
payload <- list(
timestamp = format(Sys.time(), "%Y-%m-%dT%H:%M:%SZ", tz = "UTC"),
session = session$token,
event = event,
...
)
cat(jsonlite::toJSON(payload, auto_unbox = TRUE), "\n", file = stderr())
}The implementation is deliberately minimal. Each log event is a
single JSON object on a single line — no multi-line stack traces, no
ANSI color codes, no cat(paste0(...)) chains. The
auto_unbox = TRUE argument ensures that scalar values are
emitted as JSON scalars (not single-element arrays), which simplifies
downstream parsing.
The Observability Invariant. Every user-initiated state transition must emit a structured log event. If a state change occurs without a corresponding log entry, the system’s behavior is unobservable in production — and an unobservable failure is indistinguishable from a nonexistent one.
Observability Insight
Structured logs transform debugging from an art into a query. The
difference between cat("user opened filter") and
{"event":"VALIDATION_CHANGE","session":"abc123","is_valid":false}
is the difference between reading a novel and querying a database. Both
contain the same information; only one is machine-parseable at
scale.
ALCOA+ Compliance Mapping
For regulated industries, the structured logging layer satisfies core ALCOA+ data integrity principles out of the box:
| ALCOA+ Principle | How This System Satisfies It |
|---|---|
| Attributable | Every event carries a unique session token that identifies the originating user session |
| Legible | JSON-line format is both human-readable and machine-parseable — no binary encoding |
| Contemporaneous | ISO-8601 UTC timestamps are generated at event time, not retroactively |
| Original | Logs are emitted directly to stderr — the
original record, not a copy or summary |
| Accurate | FILTER_SUCCESS records the complete
selection vector, not a derived or aggregated value |
| Complete | The Observability Invariant ensures every state transition emits an event — no gaps |
| Consistent | All events share the same JSON schema, enabling uniform downstream processing |
| Enduring | stderr output persists in container logs
(CloudWatch, ELK) beyond the session lifetime |
| Available | JSON-lines format is queryable by any standard tool
(jq, CloudWatch Insights, Datadog) |
6. The “Green Light” Pipeline
Our CI/CD pipeline enforces a Strict Production Gate — every stage is a mandatory pass/fail checkpoint. No stage is advisory. No warning is suppressed. A single failure at any stage halts the entire pipeline and prevents deployment.
The pipeline is designed around a principle borrowed from safety-critical engineering: default-deny. The application is assumed to be broken until every gate proves otherwise. This is the opposite of the typical CI pattern, where tests are informational and deployment proceeds regardless of warnings.
Linting — 100% styler Compliance
Checked against the styler tidyverse guide. A single non-conforming line fails the build. This is not cosmetic — consistent formatting eliminates an entire class of merge conflicts and makes code review faster. The lint check runs in under 5 seconds and catches issues that would otherwise consume reviewer attention.
Unit Tests — Full Coverage of R/validation.R
Tested in isolation via testthat. Constants drive both the
live UI and these assertions — the same VALID_CATEGORIES
vector that populates the dropdown also defines the boundary of valid
input in the test suite. This is the Zero Drift
principle applied to testing: if the UI boundary changes, the test
boundary changes automatically.
Integration Tests — Full Session Simulation
A real browser session via shinytest2 tests the reactive
graph end-to-end. The test opens the filter modal, selects a category,
verifies that subcategories update correctly, selects a product,
submits, and confirms the main table reflects the selection. This is not
a unit test — it exercises the full chain from UI event to server
response to DOM update.
Deployment Guard — Readiness Polling Loop
A loop polls the app’s health endpoint after push until it returns HTTP 200. This prevents the race condition where a deployment is declared “done” by the CI system before the app is actually serving traffic. The guard has a configurable timeout — if the app does not respond within 5 minutes, the deployment is marked as failed and the previous version remains active.
Smart Extras: Image Recycling + Semantic Versioning
The pipeline performs content-based image recycling: it
hashes renv.lock and Dockerfile to skip a full
container rebuild if neither has changed. This reduces CI time on
code-only changes from ~15 minutes to under 2. On every successful merge
to main, the pipeline automatically tags a semantic
version release in GitHub, creating a full audit trail of
production deployments.
Figure 4. Green Light Pipeline. Each gate is a hard fail. The deployment guard loop (rightmost node) prevents race conditions where a push is declared ‘done’ before the app is actually serving traffic. The dashed arrow from LINT to BUILD FAIL represents the default-deny principle: any gate can halt the pipeline.
The pipeline is intentionally sequential, not parallel. Each stage depends on the previous one: there is no value in running E2E tests if the code does not lint, and no value in deploying if the E2E tests fail. The sequential design also produces a clear, linear log — when a failure occurs, you know exactly which gate stopped the pipeline without parsing interleaved output from parallel jobs.
The deployment guard is not optional. Without it,
the CI system reports “deployment successful” the instant
rsconnect::deployApp() returns — but
deployApp() returns when the upload is complete,
not when the app is live. The app may still be building,
installing packages, or crashing on startup. The polling loop closes
this gap by waiting for the app to actually respond to HTTP requests
before marking the deployment as successful.
Pipeline Insight
The Green Light pipeline applies the same logic as walk-forward validation: do not declare success based on intermediate results. Walk-forward validation waits until the model has been tested on genuinely future data before reporting RMSE. The deployment guard waits until the app is genuinely serving traffic before reporting success. Both prevent premature confidence.
Qualification Mapping (IQ/OQ/PQ)
For organizations that require formal system qualification, the four pipeline stages map directly to the IQ/OQ/PQ model: Lint + Unit Tests = IQ (the system installs and configures correctly), E2E Tests = OQ (it operates as specified under controlled conditions), Deployment Guard = PQ (it performs correctly in the live production environment). The pipeline produces the evidence that a validation protocol would require — automatically, on every release, with no manual steps to skip.
7. The Statistical Parallel
This infrastructure blueprint was built in the same spirit as the statistical rigor documented in the companion piece CV vs. Proper Validation. The connection is not metaphorical — the same structural principles that prevent optimism bias in model evaluation prevent production failures in application deployment.
| Statistical Concept | Infrastructure Analogy | Why It Matters |
|---|---|---|
| Random CV admits leaked structure | PoC fails in production (env rot) | A prototype that works on the developer’s machine has ‘leaked’ the local environment into its evaluation |
| Exchangeability assumption (IID) | renv + ABI alignment = runtime
contract |
The IID assumption maps to the ABI contract: if the runtime differs from the build environment, all guarantees are void |
| Grouped CV: unseen clusters | Headless E2E: test in isolated env | E2E tests run in a fresh container with no pre-existing state — the test has never ‘seen’ the environment before |
| Walk-forward: reveals drift | Deployment Guard: continuous check | The deployment guard continuously checks whether the app is alive, revealing drift between ‘deployed’ and ‘running’ |
| Mixed-effects: structural fix | Unified Validation Engine: structural fix | Moving validation into pure functions is the same as adding random effects: it structurally accounts for variation that ad-hoc methods ignore |
| Zero Drift: constants drive tests | Single source of truth: R/constants.R |
The same constant driving both UI and tests is the infrastructure equivalent of blocking on the same variable used in deployment |
The deepest parallel is between evaluation bias and environment bias. Random CV produces an optimistic error estimate because it evaluates on a distribution that is more favorable than deployment. A PoC produces an optimistic reliability estimate because it runs in an environment that is more favorable than production. In both cases, the fix is the same: evaluate under conditions that match deployment.
The Unified Principle. Whether you are building a model evaluation pipeline or a Shiny deployment pipeline, the same law applies: the integrity of your result depends entirely on the integrity of your process. An optimistic RMSE from leaked CV folds is no different from a green CI badge from untested deployment — both create false confidence that collapses on contact with reality.
8. Summary: The Blueprint
The six pillars of the production-grade Shiny blueprint address independent failure modes. Each corresponds to a specific class of PoC failure and a verifiable engineering decision.
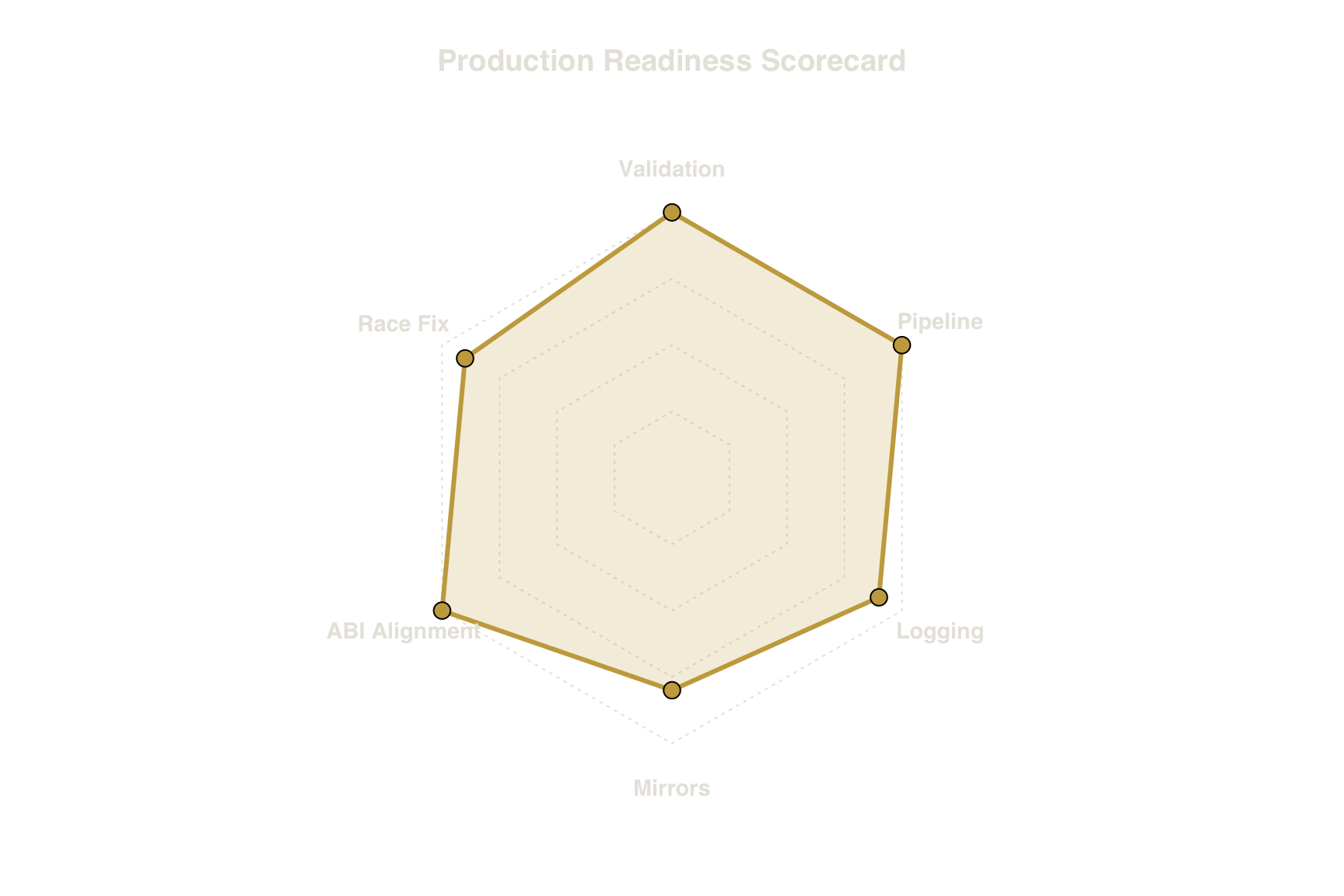
Figure 5. The Six Pillars of Production-Grade Shiny. Each pillar addresses one of the classic PoC failure modes. The radar shape shows that no single pillar dominates — production readiness requires strength across all dimensions simultaneously. A system that scores 10 on validation but 0 on logging is not ‘mostly ready’ — it is undebuggable in production.
9. Key Takeaways
-
Extract validation from the reactive graph. Pure validation functions are testable in milliseconds without a Shiny session. Embedded
if/elseblocks in observers are untestable without a browser — and untestable code is unverified code. -
Populate static UI elements at definition time. If the initial value of a dropdown does not depend on user input or database state, define it in the UI function, not in the server. This eliminates race conditions and makes the app instantly usable for both humans and automated tests.
-
Pin every dimension of your build environment. Package versions (
renv), OS ABI (Rocker image digest), and binary mirrors (PPM) are three independent axes of non-determinism. Pinning only one leaves the other two free to drift — and a single ABI mismatch can crash an otherwise correct application. -
Log structure, not prose. JSON-line logs to stderr are machine-parseable, aggregatable, and queryable.
cat("something happened")is human-readable on a single terminal and useless everywhere else. -
Default-deny your deployment pipeline. Every gate must be a hard pass/fail. Advisory warnings and suppressed errors are holes in the proof. A pipeline that “mostly passes” is a pipeline that sometimes ships broken code.
-
Close the deployment gap. The CI system’s “success” status must mean “the app is serving traffic,” not “the upload completed.” A polling loop that waits for HTTP 200 is the deployment equivalent of a time-blocked test split: it evaluates under the conditions that actually matter.
Final Takeaway
The goal of production engineering is not to make the app “work.” The goal is to make the app provably correct — at build time, at deploy time, and at runtime. Every gate, every test, and every invariant is a proof step. If any step is missing, the proof is incomplete, and the system’s reliability is an assumption, not a fact.
10. Limitations
The patterns documented above are demonstrated through a single case study — a Shiny application with categorical cascade filtering. Several scope boundaries should be noted:
- Single application type. The case study uses a modal-based filter interface with three-level categorical hierarchies. Applications with continuous inputs, real-time data streams, or multi-user collaboration may require additional engineering patterns not covered here.
- No load-testing data. The performance claims (e.g.,
“90% faster builds”) reflect build-time improvements from binary mirrors
vs. source compilation. We did not conduct formal load testing
(concurrent users, response latency under stress). Production
deployments with high concurrency requirements would need additional
infrastructure (e.g.,
ShinyProxy, load balancing). - Validation scope. While the engine demonstrates both hierarchical (cascade) and scalar (Quantity, Comment, Order Date) validation, it does not cover cross-field dependencies or temporal constraints (e.g., “end date must be after start date”). More complex form logic would require extensions to the pattern.
- Single deployment target. The CI/CD pipeline
targets shinyapps.io via
rsconnect. Kubernetes, AWS ECS, or bare-metal deployments would require different deployment guard implementations (e.g., health check endpoints, readiness probes). - No database integration. The application uses in-memory data frames. Production applications that read from databases introduce additional failure modes (connection pooling, query timeouts, schema drift) not addressed by this blueprint.
- Missing formal test coverage metrics. While the
R/validation.Rlogic is exercised bytestthatand the UI byshinytest2, the project lacks a formal coverage reporting mechanism (e.g., via thecovrpackage). In a production environment, automated coverage metrics are critical to ensure that new features or edge cases do not enter the codebase without corresponding verification gates. - No formal validation protocol. The pipeline produces qualification evidence suitable for IQ/OQ/PQ documentation, but does not include a pre-written Validation Master Plan, formal risk assessment matrix, or protocol documents aligned to GAMP 5 Category 5. Organizations operating under 21 CFR Part 11 or EU Annex 11 would need to layer these documents on top of the engineering foundation described here.
These constraints do not affect the qualitative principles — the
patterns are general — but the specific implementation (e.g., polling a
shinyapps.io URL, using renv for package management) is
tailored to this deployment context.
References
- Fay, C., Guyader, V., Rochette, S., & Girard, S. (2021). Engineering Shiny. CRC Press.
- Wickham, H. (2021). Mastering Shiny. O’Reilly Media.
- Wickham, H. (2024). testthat: Unit Testing for R. testthat.r-lib.org
- Hester, J. (2024). covr: Test Coverage for R Packages. covr.r-lib.org
- Ooms, J. (2024). jsonlite: A Simple and Robust JSON Parser and Generator for R. CRAN
- Seo, J., & Persson, M. (2024). shinyFeedback: Display User Feedback in Shiny Applications. CRAN
- Müller, K., & Walther, L. (2024). styler: Non-Invasive Pretty Printing of R Code. styler.r-lib.org
- Iannone, R. (2024). DiagrammeR: Graph and Network Visualization. rich-iannone.github.io/DiagrammeR/
- Posit PBC. (2024). renv: Project Environments for R. rstudio.github.io/renv/
- Posit PBC. (2024). rsconnect: Deploy Content to Posit Connect, shinyapps.io, and RPubs. rstudio.github.io/rsconnect/
- Posit PBC. (2024). shinytest2: Testing for Shiny Applications. rstudio.github.io/shinytest2/
- Posit PBC. (2024). Posit Package Manager. packagemanager.posit.co
- Rocker Project. (2024). Rocker: R Configurations for Docker. rocker-project.org